
An Engineer's Guide to Web Caching at Scale
An Engineer's Guide to Web Caching at Scale
Caching is one of the hardest problems in computer science. It's a delicate balance, a constant trade-off between performance and data freshness. As Phil Karlton famously said, "There are only two hard things in Computer Science: cache invalidation and naming things." Get it right, and your application is lightning-fast, scalable, and resilient. Get it wrong, and you're serving stale data, crashing servers, and fielding angry customer calls.
In this post, we'll explore the real-world evolution of a caching strategy for a major e-commerce retailer. We'll move from the simplest implementation to a sophisticated, multi-layered approach, showing how each layer solves a specific problem. Some of this is simplified for the sake of clarity—the reality is often even more complex!
At the heart of every caching decision lies a fundamental set of trade-offs. Think of it as a balancing act across two spectrums:
-
The Performance Spectrum: This ranges from the fastest cache (like the user's browser), which has the highest performance impact, to the slowest source (your backend database), which has the least impact on perceived speed.
-
The Data Freshness Spectrum: This ranges from potentially stale data that has been sitting in a cache to real-time data pulled directly from the source of truth.
Our goal is always the same: serve content from the fastest possible point on the performance spectrum that still meets the data freshness requirements for that specific piece of content.
The Business Case for Caching
In the beginning, you have a simple setup that works. But then, success happens. The business wants to expand into new markets, marketing launches a massive new campaign, or a push notification goes out to millions of app users. Suddenly, your servers are melting.
This is where caching becomes critical. It allows you to:
- Reduce Cost Per Request: Fewer requests hitting your expensive backend resources means lower infrastructure costs.
- Maximize Throughput: By reducing the load on your origin servers, you increase their capacity to handle essential, non-cacheable requests.
- Relieve Downstream Pressure: Complex requests often trigger a cascade of internal service calls (e.g., a user lookup before an order lookup). Caching the final result prevents this N+1 problem from overwhelming your internal systems.
- Protect Against Spikes: Timed sales and promotions can bring a flood of traffic. Caching acts as a shock absorber, smoothing out these spikes and preventing your infrastructure from collapsing under the load.
The Building Blocks
Before diving into the complex stuff, let's cover the fundamental layers of caching available to any web application.
- Server Caches: Each server holds its own cache in memory. This is fast but limited in scale. In a serverless or multi-process environment (like Lambda), this can be ineffective as each instance has a "cold" cache. An external cache like Redis solves this by providing a shared, out-of-process cache.
- CDN Rules: The Content Delivery Network (CDN) is your first line of defense. It caches content at the "edge," geographically close to your users. You control its behavior with headers like Cache-Control and by defining how it uses the URL path, query strings, and headers to create a unique cache key.
- Browser Caching: The fastest cache of all is the one on the user's own device. Response headers can instruct the browser on how and for how long to cache a resource locally. Be warned: browsers can sometimes behave unpredictably.
- The Combined Effect: These rules don't exist in a vacuum. A request can be served by the browser, the CDN, or your origin server, and the interplay between these layers determines your overall cache hit ratio.
The Modern Web
Modern frameworks like Next.js give us powerful rendering strategies, each with its own caching implications:
- Static Site Generation (SSG): Pages are generated at build time. The resulting HTML files are static assets that can be cached "forever" (or until the next deployment). This is the fastest and most cacheable option.
- Server-Side Rendering (SSR): Pages are generated on the server for each incoming request. By default, these are not cached.
- Client-Side Rendering (CSR): After the initial page load, navigation is often handled on the client-side. JavaScript fetches data from an API and updates the view. These API calls are not cached by default.
- Incremental Static Regeneration (ISR): A hybrid approach where pages are statically generated but can be revalidated in the background after a set time. This allows for a balance between freshness and performance.
- Edge Functions: Running code at the edge (e.g., Vercel Edge Functions) allows for custom caching logic closer to the user, reducing latency and offloading work from your origin servers.
A Caching Journey: The Beginning
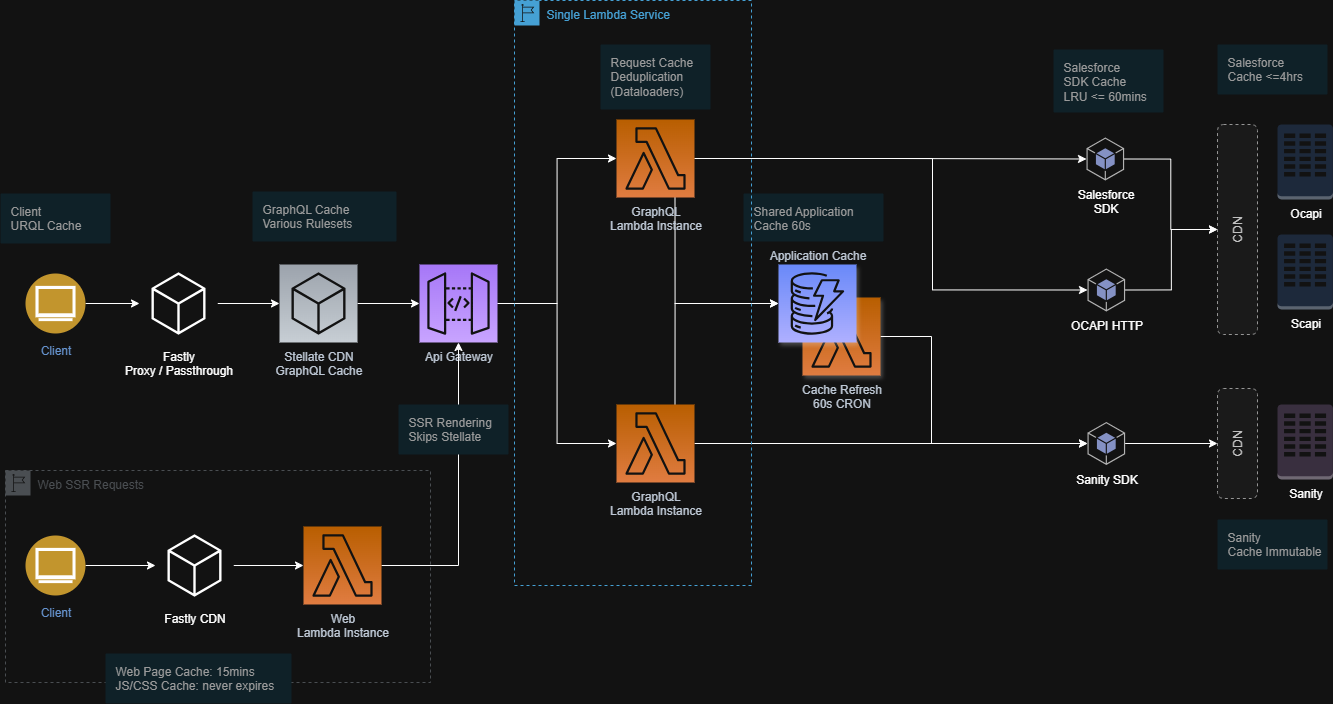
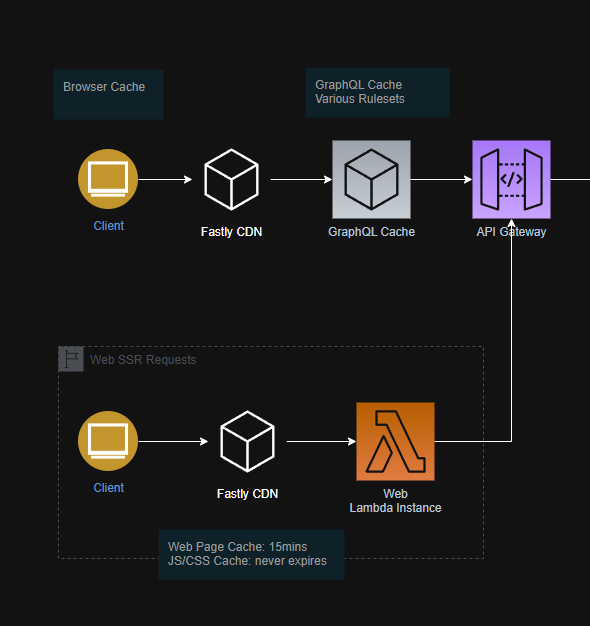
Let's imagine a large retail site at the start of its journey. There's no CDN and no caching. Every request goes directly to the web servers, which in turn call a GraphQL API. This API aggregates data from multiple sources like a headless CMS (Sanity) and an e-commerce platform (Salesforce Commerce Cloud).
At this stage, resource usage is directly proportional to traffic. The only "caching" is what the browser does automatically for some static files like CSS, images, and scripts. These are the easiest candidates for our first caching improvement.
Static File Caching
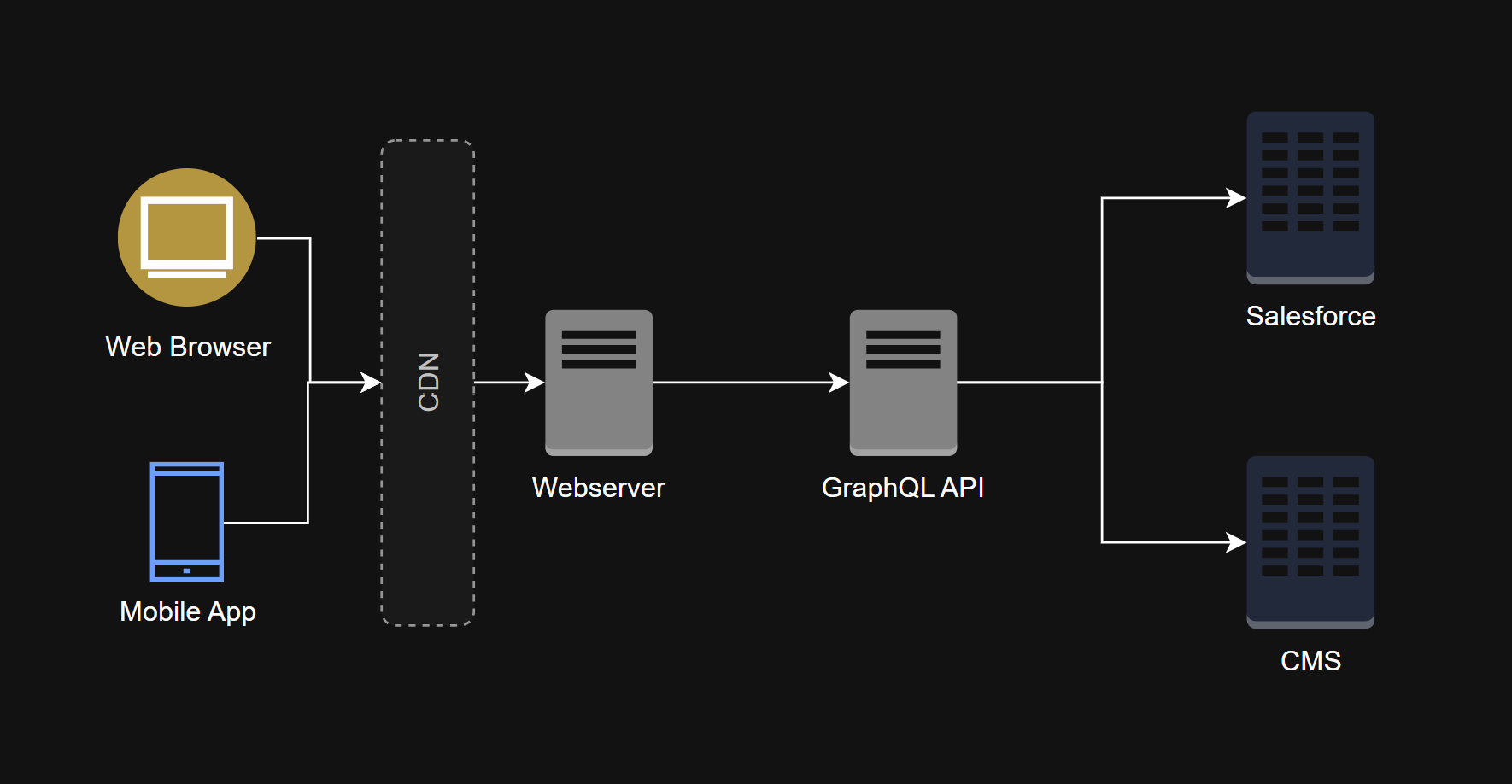
The first step and most basic step is to put a CDN in front of our static assets origin.
- First Request: A user requests styles.css. The request hits the CDN, which doesn't have the file. The CDN retrieves it from the S3 bucket, sends it to the user, and caches it.
- Second Request: Another user requests the same file. The request hits the CDN, which serves the file directly from its cache. The origin is never touched.
Most modern build tools generate unique filenames for assets with each deployment (e.g., styles.a1b2c3d4.css). This allows us to tell the CDN to cache these files forever. A common mistake is deleting old files on deployment; they should be left in place so users who still have the old site HTML cached don't experience broken pages.
If you are using a platform like Vercel, you should enable Skew Protection so each deployment is locked to the correct version of assets you deployed previously.
CDN Shielding
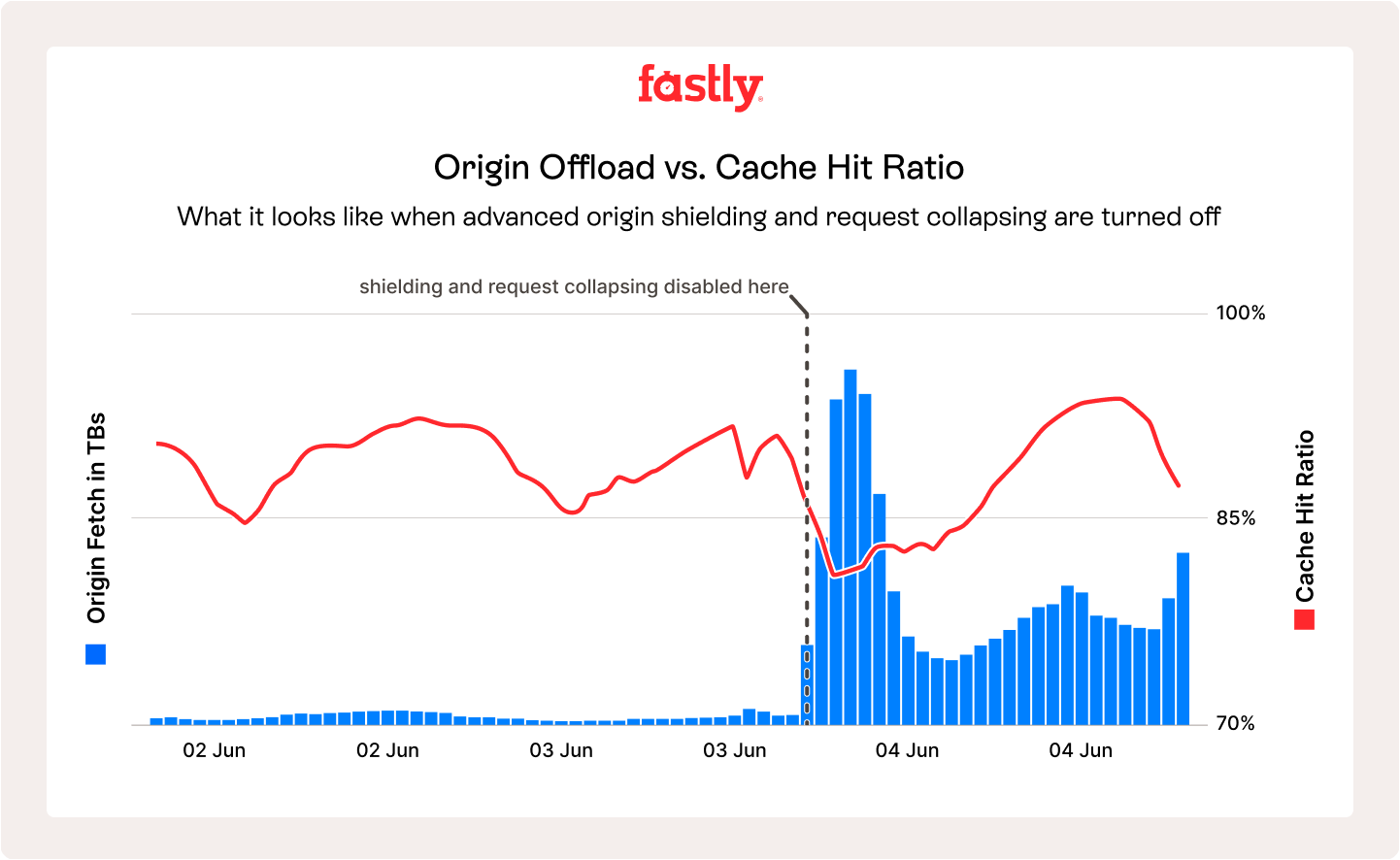
CDNs have a global network of "edge" locations. Without shielding, a request for a file from a user in London and another in Tokyo would cause both the London and Tokyo edge locations to request the file from your origin server.
Origin shielding solves this by designating a primary CDN location that is the only one allowed to request content from your origin. All other edge locations will request from the shield, further reducing the load on your resources.
Some providers also refer to this feature as “request collapsing”.
Static Generated Pages (SSG)
The next step is to cache entire pages. For pages generated at build time (SSG), we can treat the HTML file just like a static asset. However, unlike our uniquely named CSS files, the URL for about-us.html stays the same across deployments. This is typically non-product pages on an e-commerce site, like About Us, Contact, FAQ, etc.
This means that with every new deployment, we must actively purge or invalidate the old page in the CDN's cache. Different CDNs provide different mechanisms for this, such as clearing by URL or by tags.
The API Layer
Analytics will almost always show that your highest volume pages are the Product Listing Pages (PLPs) and Product Display Pages (PDPs). This is where we need to focus our next efforts.
A Product Dislay Page (PDP) is composed of many different pieces of data, each with a different "freshness" requirement.
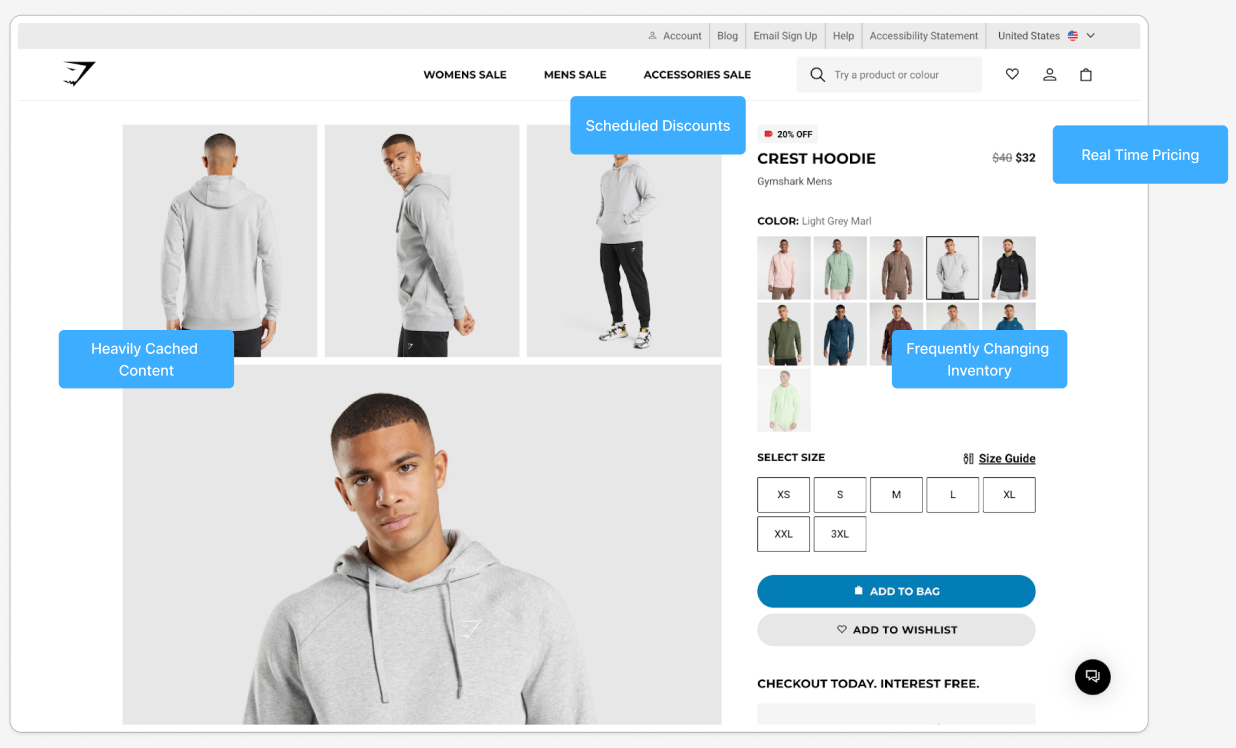
When this page is server-side rendered (SSR), all this data is fetched and assembled on the server. We can cache the entire SSR page output at the CDN, but for how long? Product descriptions change infrequently, but inventory can change every second.
This is where API caching comes in. Instead of just caching the final HTML, we cache the underlying API responses. Client-side navigation and mobile apps, which hit the API directly, also benefit from this. For GraphQL specifically, there are well-established caching best practices to consider.
We can also use a provider service like Stellate (formerly GraphCDN) which acts as a caching layer specifically for GraphQL APIs.
But what about that real-time inventory data or promotions? A common solution is to separate the API queries that make up the entire page and group them by how often the data changes:
- Page Content: Headers, footers (cache for a long time).
- Product Data: Name, images, description (cache for a medium amount of time, invalidate on product updates).
- Personalized Data: Pricing, promotions (cache for a short time, or not at all).
- Near Real-Time Data: Inventory (very short cache TTL, or no cache).
Our SSR requests can still hit the backend API directly to get the absolute freshest data on the first page view, while subsequent requests (both SSR and client-side) can be served from the API cache, drastically reducing load.
Caching Complex Pages
Product Listing Pages (PLP) are the hardest to cache due to a mix of infinite scroll, pagination, and especially product filters.
The number of possible unique URLs grows exponentially with each additional filter. For example, if you have 5 filters (size, color, brand, price range, rating) and each has 10 options, that's 10^5 unique combinations for just one category page! The sheer number of unique query string combinations means the cache hit rate for both SSR pages and API calls will be very low.
However, we can make some initial strides in improving this:
- Sort Query Strings: Start by sorting query strings. A CDN treats
/products?size=m&color=blueand/products?color=blue&size=mas two different URLs. We can implement logic at the edge to sort query string parameters alphabetically before they are used in the cache key, ensuring they are treated as the same page. - Strip Tracking Query Strings: URLs from ads often contain unique tracking parameters (e.g.,
fbclid,gclid). These are unique per user and will kill your cache. At the CDN level, configure rules to strip these known parameters from the cache key.
These optimizations help, but for highly faceted pages, the ultimate solution often lies even deeper.
Going Deeper: Downstream Caching
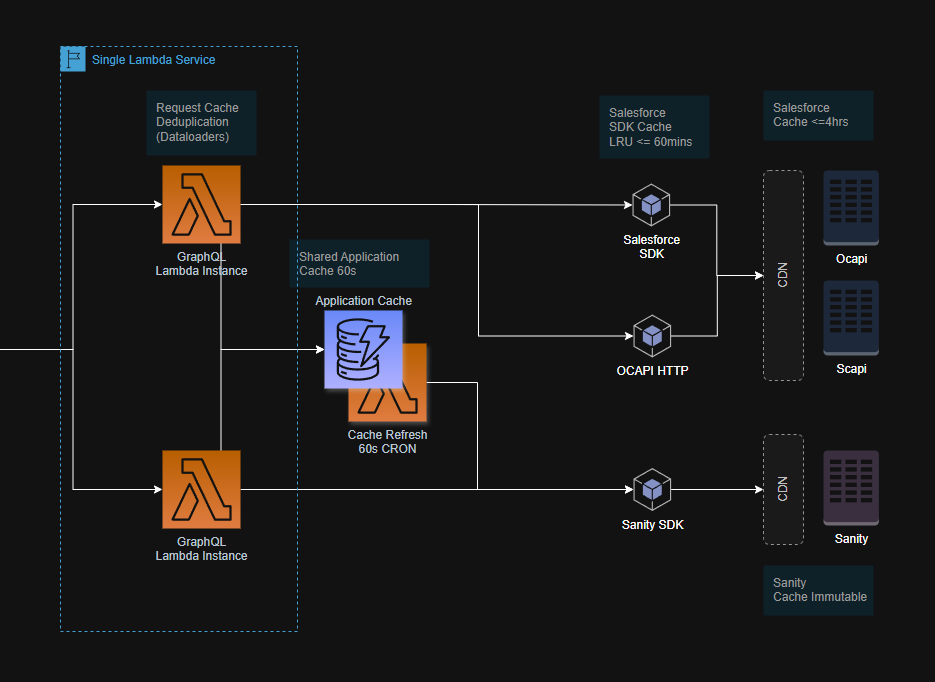
When the CDN and API layers aren't enough, you must cache further down the stack.
- Interprocess Caching: Within your API, use a shared cache like Redis to store the results of expensive operations or data fetched from underlying datastores.
- Datastore Caching: Most underlying data platforms, whether it's a database, Salesforce, or a CMS, have their own caching layers. Leverage them to reduce load on the source of truth.
Cache Invalidation
A cache is useless if you can't update it. Reliable and predictable cache-busting is crucial
Most of the time, we can safely rely on a TTL (Time To Live), where content expires after a set time. But sometimes you need immediate updates. This is where event-driven cache invalidation comes in. When data changes in your CMS or PIM, it should trigger an event to purge the relevant content from the cache. But it's important to note that this comes with increased server demand and backend pressure. You have to decide if the data change is worth the cost of immediate invalidation.
- Not Critical: A spelling error on an FAQ page. Let the TTL handle it.
- Critical: An accidental 100% discount that was meant to be 10%. Purge the cache immediately!
- Timed Events: A new product launch or sale starting at a specific time. Use scheduled jobs to clear caches at the right moment.
Some platforms, like Vercel, offer On-Demand ISR which allows you to programmatically trigger a revalidation of a specific page. This can be used in combination with features from CMS platform features like Sanity's Content Releases to schedule content updates and automate cache invalidation.
The Final Form
After this journey, our caching story is a robust, multi-layered strategy that protects our origin, serves users quickly, and handles massive traffic spikes with ease. Each layer serves a purpose, from the browser on the user's machine to the database at the heart of our system.